Data Warehousing Interview Questions


5 min read

Q: What is a data warehouse?
Fetch all the data from different OLTPs, make it coherent (in a consistent manner), load to the Data warehouse, and generate the Reports from the Data Warehouse

Data warehousing is a separate database that is specially structured for reporting and analysis.
Data warehousing contains both current and historical data.
It is also called an OLAP database or reporting database.
• Generally, we will define DWH database by using multi-dimensional Dimensional Modeling
Q: What is OLTP?
LTP stands for Online Transactional Process, which stores transactional data. The Operational systems are where the data is put.
Q: What is OLAP?
OLAP stands for Online Analytical Process, which stores analytical data that is used for analysis and reporting. The data warehouse is where we get the data.
Q: What is the need for a data warehouse?
Let us assume ‘ABC’ bank operates in multiple countries. And let us say Country 1 data is residing in OLTP1, Country 2 data is in OLTP2, and Country 3 data is in OLTP3. If one day ABC Bank requires consolidated reports, we need to go for data warehousing.
Q) Why do we never create reports at the top of OLTPS?
OLTP Systems does not maintain a complete history in order to have better transaction performance. So it is not possible to analyze the data completely for a wide range of.
Q: What are the issues we face when creating reports on top of OLTPS?
We are fetching the data from multiple transactional systems to generate a consolidated report; obviously, it takes some time to get the final consolidated report. As the OLTP systems are highly normalized, to get the report output, we need to join a larger number of tables. Also, it is not recommended to insert and retrieve data from the same system at the same time.
Q) What are the benefits of OLAP?
OLAP will maintain a complete history so that we can make better analyses using complete data. There will be no performance issues because we have complete data from all the transactional sources in the data warehouse. Completely De-Normalized
• The databases that are used for reporting and analysis are called OLAP databases.
•OLAP databases contain entire organization data.
•OLAP database data is summarized.
•OLAP databases are designed using multi-dimensional modeling.
•OLAP databases are highly denormalized.
• Query performance is good in OLAP databases.
Q) ER-Modelling?
Entity Relationship Modeling is used to design OLTP databases. data is highly normalized

Q) Dimension modeling?
Dimensional Modeling is used to design OLAP databases. Dimensional modeling is a particular design methodology of data modeling wherein the goal of modeling is to improve query performance.
Q) Star Schema?
A star schema is a data warehouse database design that contains a centrally located fact table that is surrounded by multiple dimension tables. In the star schema, all the dimensional tables directly connect to the fact table.
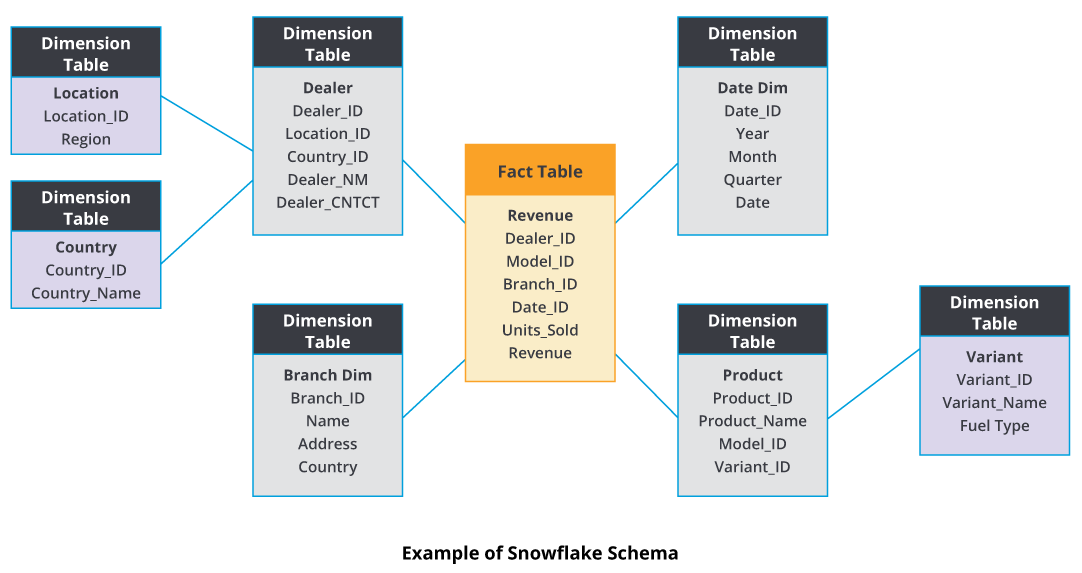
Q) Snow-Flex Schema?
A snowflake schema consists of a fact table surrounded by multiple dimension tables that can be connected to other dimension tables. In the snowflake schema, some of the dimensions will not directly connect to the fact table. When dimension tables store a large number of rows with redundancy of data and space is such an issue, we can use the Snowflake schema to save space.
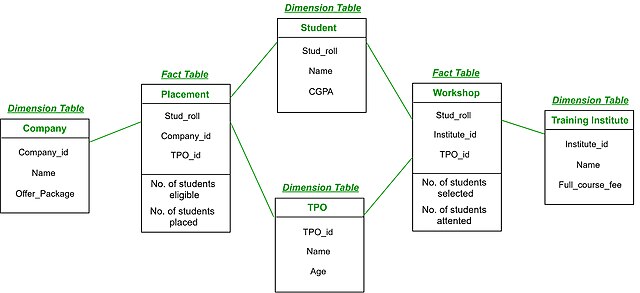
Q) Galaxy Schema?
This schema is viewed as a collection of stars; hence, it is called the Galaxy Schema or the Fact Constellation Schema. In a Galaxy schema, a single dimension table is shared with multiple fact tables.
Q: What is dimension?
A dimension is descriptive data that describes the key performance indicators, known as facts. E.g., product, customer name, date, etc.
Q) 5. What are the different types of dimension tables in the context of data warehousing?

Slowly Changing Dimension
Conformed Dimension
Degenerate Dimension
Junk Dimension
Role-playing Dimension
Static Dimension
Shrunken Dimension
Q: What is a fact table?
A fact is something that is measurable or quantifiable. Fact is the metric that business users would use for making business decisions
Q) Difference between fact and Dimension Table?
| fact Table | Dimension Table |
| It contains the attributes' measurements, facts, or metrics. | It is the companion table that has the attributes that the fact table uses to derive the facts. |
| The data grain (the most atomic level at which facts may be defined) is what defines it. | It is detailed, comprehensive, and lengthy. |
| It is used for analysis and decision-making and contains measures. | It contains information regarding a company's operations and procedures. |
| It contains information in both numeric and textual formats. | It only contains textual information. |
| It has a primary key that works as a foreign key in the dimension table. | It has a foreign key that is linked to the fact table's primary key. |
| It stores the filter domain and report labels in dimension tables. | It organizes the atomic data into three-dimensional structures. |
| It does not have a hierarchy. | It has a hierarchy. |
| It has fewer attributes than a dimension table. | It has more attributes than a fact table. |
| It has more records as compared to a dimension table. | It has fewer records than a fact table. |
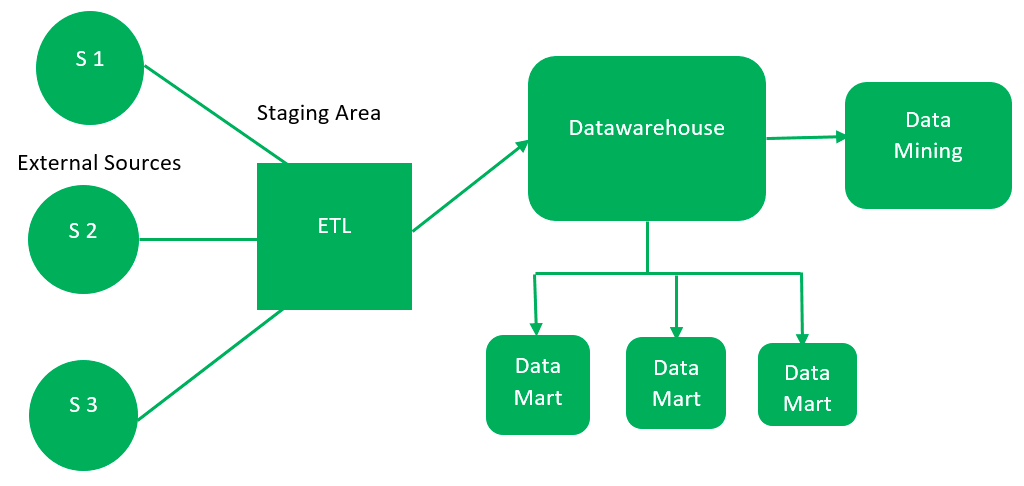
Q: What is a data mart?
A data mart is an access layer that is used to get data out to users. It is presented as an option for large data warehouses, as it takes less time and money to build. However, there is no standard definition of a data mart, which differs from person to person.
In a simple word, a data mart is a subsidiary of a data warehouse. The data mart is used for the partition of data that is created for a specific group of users.
- Data marts are a subset of the DWH database.
2. Data marts contain one subject area of information.
- Data marts are used to improve performance.
4. The creation of data marts is optional in DWH projects.
Types of data marts:
1. Dependent Data Mart.
2. Independent Data Mart
Dependent Data Mart
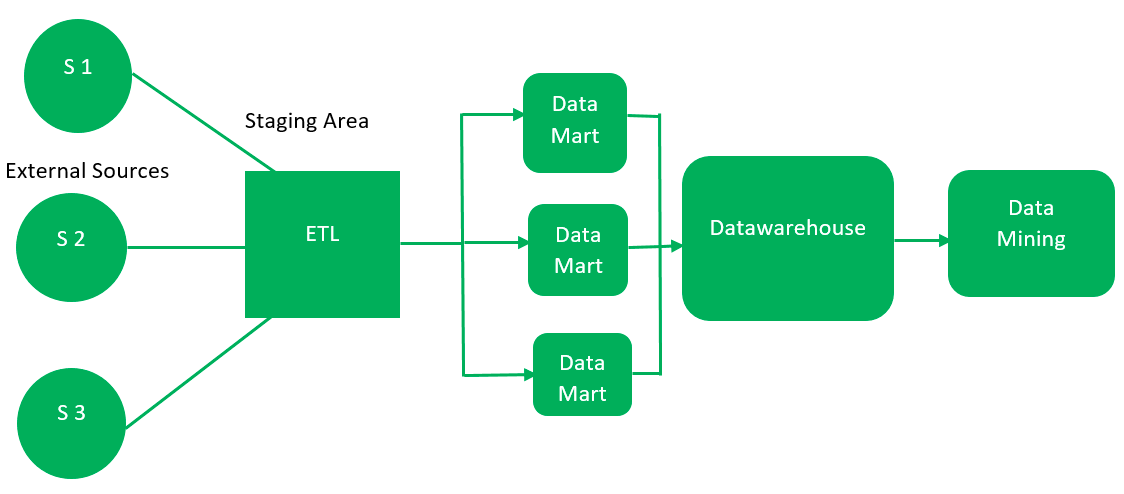
Independent Data Mart